Into the Supercontinuum
Some good news: we got funded to purchase a supercontinuum IR source and a high-speed IR camera. The idea is to couple the light source into a spectrometer after being absorbed by flow, allowing for fast and easy broadband absorption spectra.
I had hoped that NKT would have an IR supercontinuum source available, but apparently they have stopped supplying it for some reason (perhaps the power was lower than they would have liked, or there may have been other problems that I’m unaware of). I have managed to find a French supplier of these sources, so hopefully I’ll still be able to do it. It would be great to be able to see entire vibrational bands of CO2 and CO with this source. CO has bands at 2.3 microns and CO2 at 2.0, and both have bands around 4-4.5 microns. If I can hit that wavelength region, I should be able to hit both species and look at Mars entry problems in this region. The really nice thing about getting so much spectral information in the IR is that you can see any vibrational nonequilibrium in the flow, and absorption is strong, so low density flows can be measured. It may be difficult to avoid water vapour at these wavelengths, however.
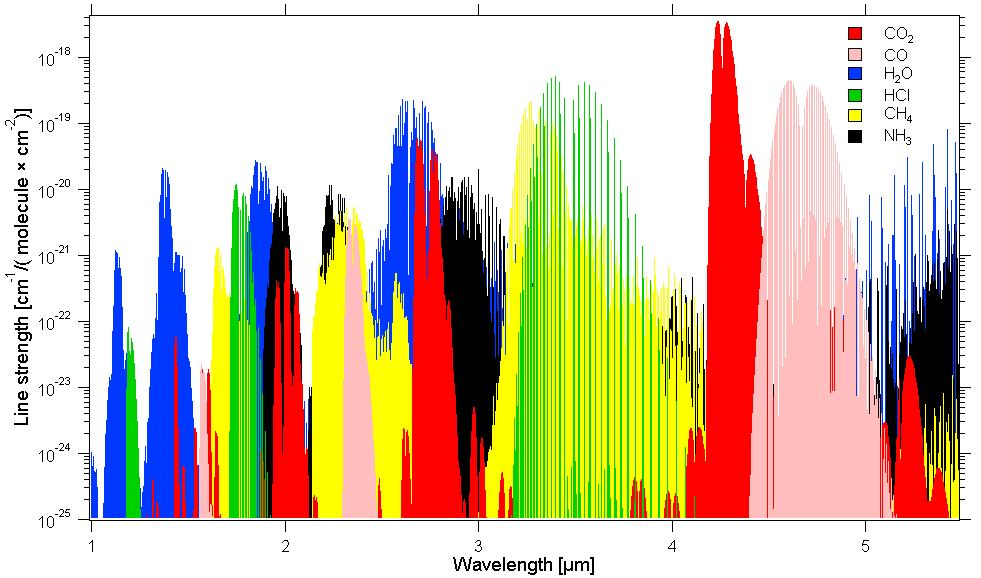
from Roller et al. (2002) Applied Optics 41(28):6018.
Now I need to do the maths to make sure that we get enough absorption signal and that the source puts enough light out to be detected by the camera over the intended wavelength range, and to find the filters I need to get to limit the detected wavelengths.
This would be a good project for an Australian PhD student with an interest in laser diagnostics and hypersonics. Contact me if you are interested.